Designing Schemas
This is Part 2 of a guide on migrating from PostgreSQL to ClickHouse. This content can be considered introductory, with the aim of helping users deploy an initial functional system that adheres to ClickHouse best practices. It avoids complex topics and will not result in a fully optimized schema; rather, it provides a solid foundation for users to build a production system and base their learning.
The Stack Overflow dataset contains a number of related tables. We recommend migrations focus on migrating their primary table first. This may not necessarily be the largest table but rather the one on which you expect to receive the most analytical queries. This will allow you to familiarize yourself with the main ClickHouse concepts, which are especially important if you come from a predominantly OLTP background. This table may require remodeling as additional tables are added to fully exploit ClickHouse features and obtain optimal performance. We explore this modeling process in our Data Modeling docs.
Establish initial schema
Adhering to this principle, we focus on the main posts table. The Postgres schema for this is shown below:
CREATE TABLE posts (
Id int,
PostTypeId int,
AcceptedAnswerId text,
CreationDate timestamp,
Score int,
ViewCount int,
Body text,
OwnerUserId int,
OwnerDisplayName text,
LastEditorUserId text,
LastEditorDisplayName text,
LastEditDate timestamp,
LastActivityDate timestamp,
Title text,
Tags text,
AnswerCount int,
CommentCount int,
FavoriteCount int,
ContentLicense text,
ParentId text,
CommunityOwnedDate timestamp,
ClosedDate timestamp,
PRIMARY KEY (Id),
FOREIGN KEY (OwnerUserId) REFERENCES users(Id)
)
To establish the equivalent types for each of the above columns, we can use the DESCRIBE command with the Postgres table function. Modify the following command to your Postgres instance:
DESCRIBE TABLE postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
SETTINGS describe_compact_output = 1
┌─name──────────────────┬─type────────────────────┐
│ id │ Int32 │
│ posttypeid │ Nullable(Int32) │
│ acceptedanswerid │ Nullable(String) │
│ creationdate │ Nullable(DateTime64(6)) │
│ score │ Nullable(Int32) │
│ viewcount │ Nullable(Int32) │
│ body │ Nullable(String) │
│ owneruserid │ Nullable(Int32) │
│ ownerdisplayname │ Nullable(String) │
│ lasteditoruserid │ Nullable(String) │
│ lasteditordisplayname │ Nullable(String) │
│ lasteditdate │ Nullable(DateTime64(6)) │
│ lastactivitydate │ Nullable(DateTime64(6)) │
│ title │ Nullable(String) │
│ tags │ Nullable(String) │
│ answercount │ Nullable(Int32) │
│ commentcount │ Nullable(Int32) │
│ favoritecount │ Nullable(Int32) │
│ contentlicense │ Nullable(String) │
│ parentid │ Nullable(String) │
│ communityowneddate │ Nullable(DateTime64(6)) │
│ closeddate │ Nullable(DateTime64(6)) │
└───────────────────────┴─────────────────────────┘
22 rows in set. Elapsed: 0.478 sec.
This provides us with an initial non-optimized schema.
Without a
NOT NULL Constraint, Postgres columns can contain Null values. Without inspecting row values, ClickHouse maps these to equivalent Nullable types. Note that the primary key is not Null, which is a requirement in Postgres.
We can create a ClickHouse table using these types with a simple CREATE AS EMPTY SELECT command.
CREATE TABLE posts
ENGINE = MergeTree
ORDER BY () EMPTY AS
SELECT * FROM postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
This same approach can be used to load data from s3 in other formats. See here for an equivalent example of loading this data from Parquet format.
Initial load
With our table created, we can insert the rows from Postgres into ClickHouse using the Postgres table function.
INSERT INTO posts SELECT *
FROM postgresql('<host>:<port>', 'postgres', 'posts', '<username>', '<password>')
0 rows in set. Elapsed: 1136.841 sec. Processed 58.89 million rows, 80.85 GB (51.80 thousand rows/s., 71.12 MB/s.)
Peak memory usage: 2.51 GiB.
This operation can place a considerable load on Postgres. Users may wish to backfill with alternative operations to avoid impacting production workloads e.g. export a SQL script. The performance of this operation will depend on your Postgres and ClickHouse cluster sizes and their network interconnect.
Each
SELECTfrom ClickHouse to Postgres uses a single connection. This connection is taken from a server-side connection pool sized by the settingpostgresql_connection_pool_size(default 16).
If using the full dataset, the example should load 59m posts. Confirm with a simple count in ClickHouse:
SELECT count()
FROM posts
┌──count()─┐
│ 58889566 │
└──────────┘
Optimizing types
The steps for optimizing the types for this schema are identical to if the data has been loaded from other sources e.g. Parquet on S3. Applying the process described in this alternate guide using Parquet results in the following schema:
CREATE TABLE posts_v2
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
COMMENT 'Optimized types'
We can populate this with a simple INSERT INTO SELECT, reading the data from our previous table and inserting into this one:
INSERT INTO posts_v2 SELECT * FROM posts
0 rows in set. Elapsed: 146.471 sec. Processed 59.82 million rows, 83.82 GB (408.40 thousand rows/s., 572.25 MB/s.)
We don't retain any nulls in our new schema. The above insert converts these implicitly to default values for their respective types - 0 for integers and an empty value for strings. ClickHouse also automatically converts any numerics to their target precision.
Primary (Ordering) Keys in ClickHouse
Users coming from OLTP databases often look for the equivalent concept in ClickHouse. On noticing that ClickHouse supports a PRIMARY KEY syntax, users might be tempted to define their table schema using the same keys as their source OLTP database. This is not appropriate.
How are ClickHouse Primary keys different?
To understand why using your OLTP primary key in ClickHouse is not appropriate, users should understand the basics of ClickHouse indexing. We use Postgres as an example comparison, but these general concepts apply to other OLTP databases.
- Postgres primary keys are, by definition, unique per row. The use of B-tree structures allows the efficient lookup of single rows by this key. While ClickHouse can be optimized for the lookup of a single row value, analytics workloads will typically require the reading of a few columns but for many rows. Filters will more often need to identify a subset of rows on which an aggregation will be performed.
- Memory and disk efficiency are paramount to the scale at which ClickHouse is often used. Data is written to ClickHouse tables in chunks known as parts, with rules applied for merging the parts in the background. In ClickHouse, each part has its own primary index. When parts are merged, the merged part's primary indexes are also merged. Unlike Postgres, these indexes are not built for each row. Instead, the primary index for a part has one index entry per group of rows - this technique is called sparse indexing.
- Sparse indexing is possible because ClickHouse stores the rows for a part on disk ordered by a specified key. Instead of directly locating single rows (like a B-Tree-based index), the sparse primary index allows it to quickly (via a binary search over index entries) identify groups of rows that could possibly match the query. The located groups of potentially matching rows are then, in parallel, streamed into the ClickHouse engine in order to find the matches. This index design allows for the primary index to be small (it completely fits into the main memory) whilst still significantly speeding up query execution times, especially for range queries that are typical in data analytics use cases. For more details, we recommend this in-depth guide.
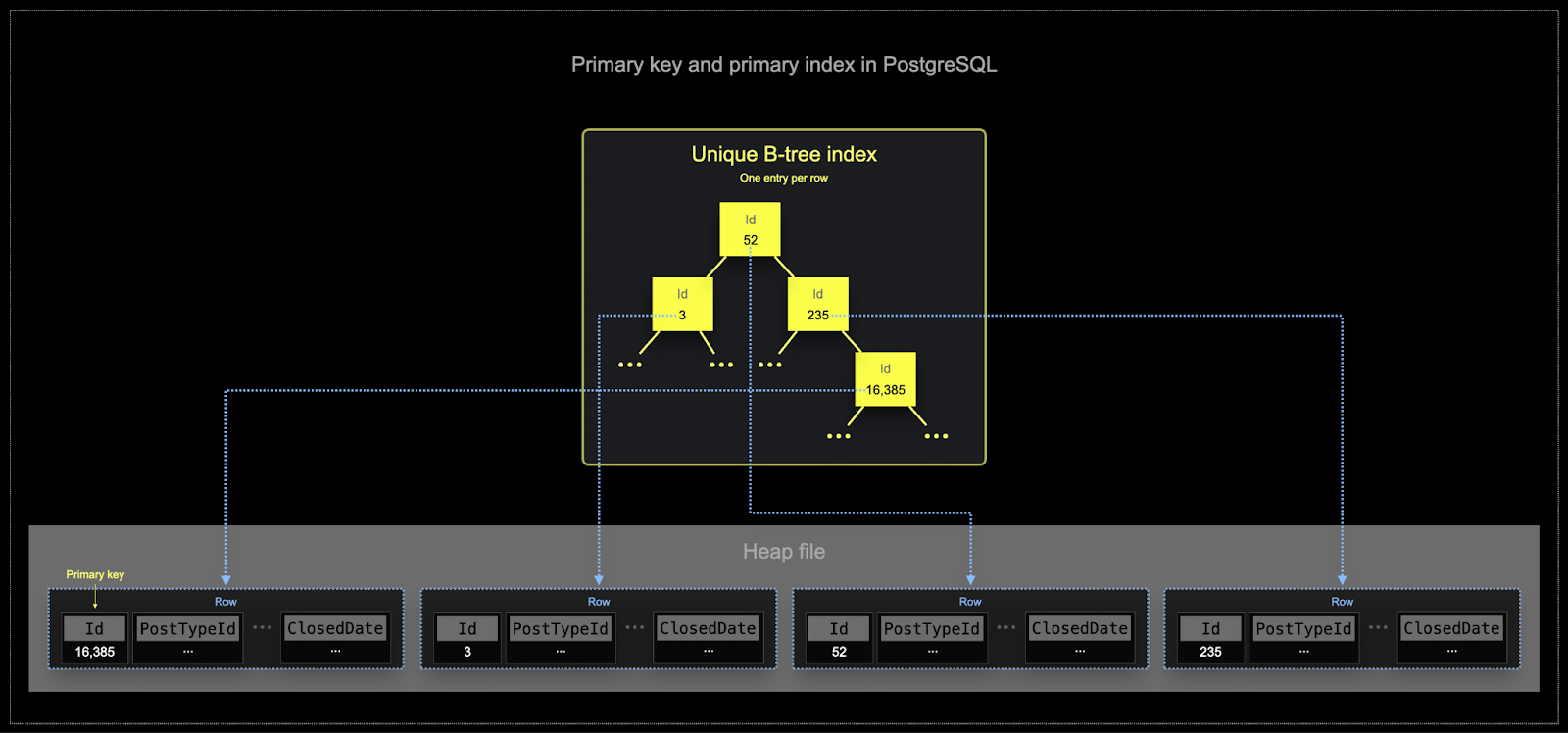

The selected key in ClickHouse will determine not only the index but also the order in which data is written on disk. Because of this, it can dramatically impact compression levels, which can, in turn, affect query performance. An ordering key that causes the values of most columns to be written in a contiguous order will allow the selected compression algorithm (and codecs) to compress the data more effectively.
All columns in a table will be sorted based on the value of the specified ordering key, regardless of whether they are included in the key itself. For instance, if
CreationDateis used as the key, the order of values in all other columns will correspond to the order of values in theCreationDatecolumn. Multiple ordering keys can be specified - this will order with the same semantics as anORDER BYclause in aSELECTquery.
Choosing an ordering key
For the considerations and steps in choosing an ordering key, using the posts table as an example, see here.
Compression
ClickHouse's column-oriented storage means compression will often be significantly better when compared to Postgres. The following illustrated when comparing the storage requirement for all Stack Overflow tables in both databases:
--Postgres
SELECT
schemaname,
tablename,
pg_total_relation_size(schemaname || '.' || tablename) AS total_size_bytes,
pg_total_relation_size(schemaname || '.' || tablename) / (1024 * 1024 * 1024) AS total_size_gb
FROM
pg_tables s
WHERE
schemaname = 'public';
schemaname | tablename | total_size_bytes | total_size_gb |
------------+-----------------+------------------+---------------+
public | users | 4288405504 | 3 |
public | posts | 68606214144 | 63 |
public | votes | 20525654016 | 19 |
public | comments | 22888538112 | 21 |
public | posthistory | 125899735040 | 117 |
public | postlinks | 579387392 | 0 |
public | badges | 4989747200 | 4 |
(7 rows)
--ClickHouse
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size
FROM system.parts
WHERE (database = 'stackoverflow') AND active
GROUP BY `table`
┌─table───────┬─compressed_size─┐
│ posts │ 25.17 GiB │
│ users │ 846.57 MiB │
│ badges │ 513.13 MiB │
│ comments │ 7.11 GiB │
│ votes │ 1.28 GiB │
│ posthistory │ 40.44 GiB │
│ postlinks │ 79.22 MiB │
└─────────────┴─────────────────┘
Further details on optimizing and measuring compression can be found here.